Účastníci našich školení a konzultací velmi často položí otázku: „Kdy a jak zahájit vyhledávání analytických tříd“? Jednoduchá šalamounská odpověď by mohla znít: „Jakmile to bude možné, protože je to pro další vývoj výhodné“. Tato odpověď je sice pravdivá, ale není nám příliš užitečná, protože sama o sobě nedefinuje přesný okamžik na časové ose vývoje a tedy neurčuje signál k vyhledávání tříd.
Zkusme tedy tento okamžik kdy a jak začít vyhledávat třídy definovat přesně.
Otázka nalézání analytických tříd úzce souvisí s jiným problémem a to tvorbou Use Case Modelu. V okamžiku, kdy analytik nalézá kontext použití systému, tj. kdy tvoří procesní model BPMN a k němu volané případy užití, zahajuje také práce na scénářích těchto případů užití z toho důvodu, aby naprogramované chování systému zapadlo správně do logiky chodu podniku a systém tak splnil ty užitky, které se od něj očekávají. Popisem děje uvnitř systému (budoucí program) analytik definuje dynamiku systému. Doporučuji jako velmi osvědčenou techniku zápisu používat tvorbu scénářů případů užití (use case scenarios), což se mi po mnohaleté zkušenosti jeví jako nejefektivnější zápis zadání dynamiky programu od analytika do realizace.
Je zřejmé, že ve scénářích případů užití analytik používá pojmy, se kterými tento scénář pracuje. Tyto prvky ve scénáři analytik identifikuje ve spolupráci s konzultantem – budoucím uživatelem systému (tj. ve smyslu Product Owner v metodice SCRUM).
Příklad takového kousku scénáře:
Obsluze se zobrazí seznam fyzických osob (rč, jméno, příjmení), obsluha vybere fyzickou osobu.
Nabízí se otázka: Jaký typ prvku z modelu UML vlastně reprezentuje tyto nalezené prvky ve scénářích případů užití, tj. v našem příkladu například „seznam fyzických osob“? O jaký typ prvku v UML (alias metaclass z metamodelu UML) se vlastně jedná?
Odpověď na tuto otázku najdeme ve vzoru Dichotomie třída instance: Scénáře případů užití pracují s instancemi z analytických tříd. Znamená to, že sice na jedné straně hovoříme o analytických pojmech obsažených ve scénářích, současně je ale také identifikujeme jako instance z analytických tříd.
Proč se tedy snažit nalézat navíc také třídy, když jsme již pojmy ve scénářích nalezli? Důvod je jednoduchý: Třídy, ze kterých pocházejí instance neboli pojmy obsažené ve scénářích, jsou vlastně meta-pravidlem neboli meta-vzorcem pro všechny instance z nich vzniklých a proto scénáře z různých případů užití musí chtě nechtě tato pravidla dodržet, což má pro další návrh dost vážné důsledky. Nemůže totiž nastat situace, aby v jednom scénáři instance z dané třídy měly úplně jiné vlastnosti než ve scénáři druhém.
Znamená to, že případy užití mají mezi sebou nepřímý vztah přes instance ze stejných tříd. Nemáme teď na mysli přímé interakce mezi případy zavedené v UML jako vztahy „include“, „extend“ a „generalizace“, ale máme na mysli vztah nepřímo odvozený přes instance ze tříd. Scénáře se totiž musí danému meta-pravidlu z modelu tříd podřídit v každém případu užití. Například pokud nalezneme mezi třídami vztah kompozice, nemohou se tyto instance mezi sebou chovat v některém ze scénářů jako kompozice a v jiném jako odkaz do seznamu.
Uveďme si příklad. Nechť jsme pomocí konzultací s budoucím uživatelem navrhli následující scénář v případu užití Editace evidovaného auta:
UC Editace auta
…
Obsluze se zobrazí seznam barev (kód, text). Obsluha vybere barvu a ta se dosadí do editovaného auta…
…
Jedná se evidentně o vztah mezi instancemi, který bude v modelu tříd navržen podle vzoru Odkaz do seznamu (slangově číselníková vazba, vztah do číselníku):
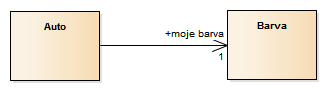 Vztah nalezený ze scénáře editace auta
Vztah nalezený ze scénáře editace auta
Nyní by si měl analytik co nejdřív tento poznatek poznačit, protože ve všech jiných scénářích, kde se objeví dvojice instancí s tímto vztahem, bude povaha vztahu Odkaz do seznamu předurčovat jejich chování. Například nechť budeme řešit modul nazvaný jako Import aut, který ze spřáteleného informačního sytému přijímá nová evidovaná auta například ve formě XML souboru. Z již nalezeného vztahu Odkaz do seznamu je nyní jasné, že barva bude zadána v této struktuře pomocí dohodnutého kódu barvy a odpovídající část scénáře bude například navržena takto:
…načte se pole kód barvy a podle tohoto kódu se v seznamu barev nalezne barva s tímto kódem, barva se dosadí do auta, pokud barva nenalezena ERR_BARVA_S_KODEM_NENALEZENA…
Scénář je díky znalosti povahy vztahu v modelu tříd vcelku jasný (tj. barva se musí najít v seznamu barev), neznáme pouze reakci na mezní stav, kdy barva s tímto kódem nebyla nalezena a nevíme, jak musíme si s budoucím uživatelem vyjasnit, má systém na tento mezní stav reagovat, tj. zda se celá věta s novým autem odmítne, nebo zda se přijme, přičemž barva nebude zadána apod.
Z uvedeného je zřejmé, že při psaní scénářů se snažíme co nejdřív nahlížet na prvky z tohoto scénáře jako na instance ze tříd a pokud tyto třídy nejsou zavedeny z předešlých scénářů, snažíme se tak učinit co nejdříve. Tímto postupem totiž určujeme pravidla pro další scénáře, které budou pracovat s instancemi z již nalezených tříd.
Závěr
Námi hledaný okamžik kdy a jak nalézat třídy jsme tímto určili vcelku přesně: Při práci s prvky ve scénářích případů užití začneme na ně nahlížet co nejdříve jako na instance ze tříd. Pokud se jedná o nové třídy, tj. zatím se s instancemi z těchto tříd nepracovalo, navrhujeme tyto třídy podle vlastností instancí daných těmito scénáři. Pokud se jedná o již zavedené třídy, tak využijeme poznatky z Class Modelu pro psaní scénářů nebo případně doplňujeme Class Model o další detaily podle poznatků z nově nalezených scénářů.
Je třeba ještě upozornit na jednu důležitou okolnost: Žádný dobrý model UML nevznikl tak, že by někdo dvě hodiny přemýšlel, koukal na prázdný papír, kouřilo se mu z hlavy a pak z něj vypadl dokonalý model. Každý model v UML vzniká neustálým opravováním původního modelu metodou „namaluj, oprav, namaluj…“. Navrhnout model tříd, který není ještě „dobrý“ (a bude opraven) není v žádném případě chybou vývojáře a není tedy příznakem jeho špatné práce, ale pouze krokem ve vývoji. Buďme proto připraveni spolu s dalšími poznatky s klidným svědomím předělat dočasné výsledky. Teprve v okamžiku revize části modelu uzavíráme tuto brainstormingovou fázi vývoje a výsledek stabilizujeme do striktní formální podoby.
Konec článku
Napsat komentář